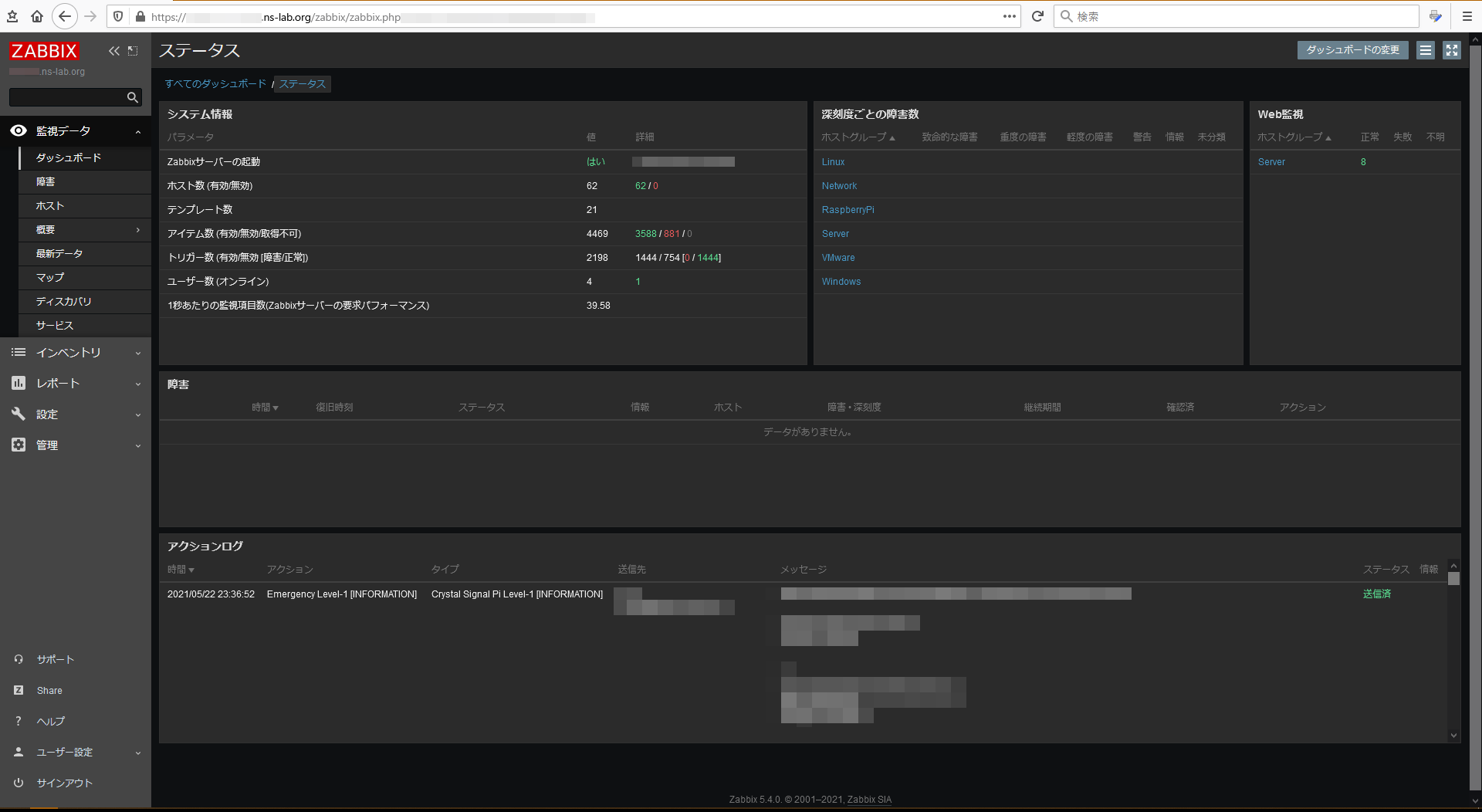
トリガーアクション切り替えの為に作成したスクリプトは、記事の一番下にダウンロードリンクを張ったので、
スクリプトが目当ての人は内容を飛ばして記事の一番したを見るべし。
………
筆者のZabbix環境は、ZabbixServerが2台・ZabbixProxyが4台の計6台で動作している。
NW機器や通信経路が単一障害点にならない様にProxy毎の監視対象をグループを作りつつ、
監視対象が停止した際は設定に従いメールアラートを発砲させるオーソドックスな構成となる。
ZabbixServer間の設定自動同期は行わず、主系・副系に手動設定する事で各々が独立している。
APIを叩いて設定同期したりDBをダンプすれば完全冗長化出来るかもしれないが、
先にも書いた通り通信経路を主系・副系で分離したりしているので完全同期すると設定が複雑になる。
その為、メンテナンス負荷を犠牲にしつつも監視対象ホストは手動登録する様にしている。
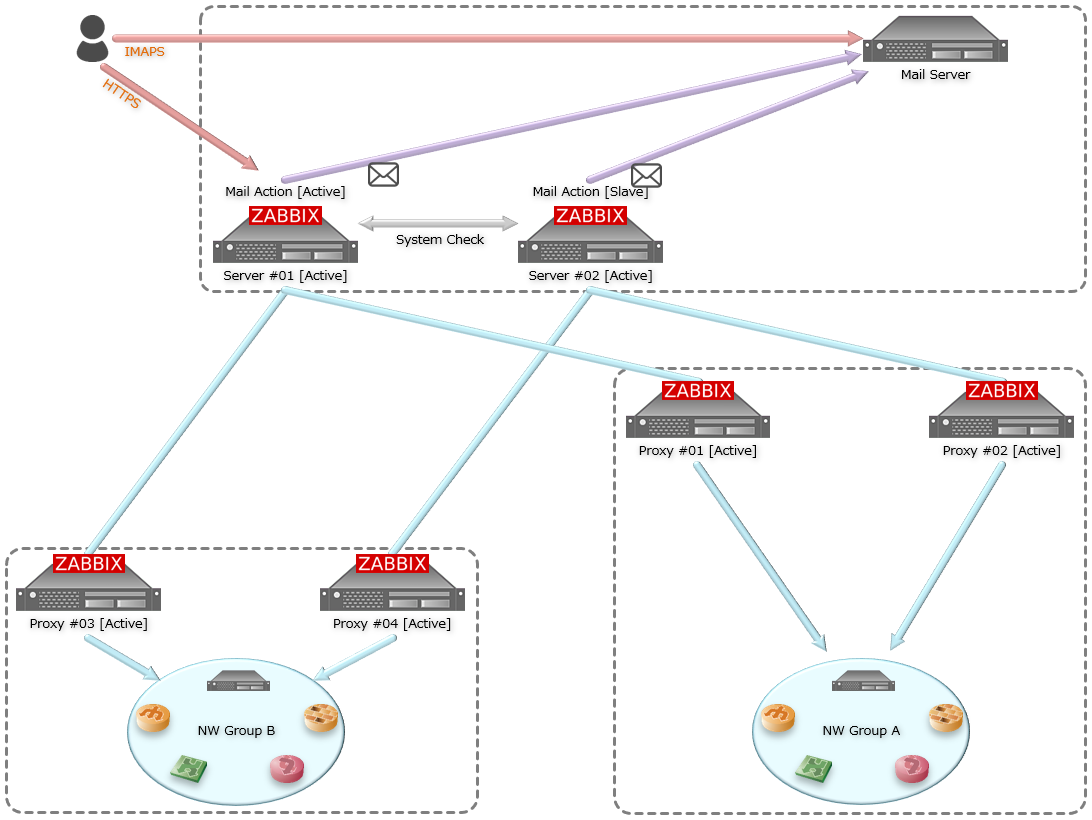
冗長化方針は置いといて、Zabbix環境の設計思想はエンタープライズ環境や他の誤自宅も似ている筈。
ちなみに、ZabbixProxyを構えずにZabbixServer単体で動かしている人も多いと思うが、
グラフを大量に配置したスクリーンを表示するとWebサーバ等がメモリを大量に使い出す上、
サーバ負荷が結構かかるのでサーバは分離する事をオススメする。
………
今回の重要ポイントとなるトリガーアクションの切り替えスクリプトは次の通り。
前提として、ZabbixServerは2台がActive-Activeで動作しており、左の主系からのみアラート発砲させている。
右の副系サーバはアラート発砲を無効化しつつも、監視アイテムは有効化されていて監視を実行している。
この時、主系サーバがダウンすると副系サーバのみとなるので、アラート発砲が届かない状態になる。
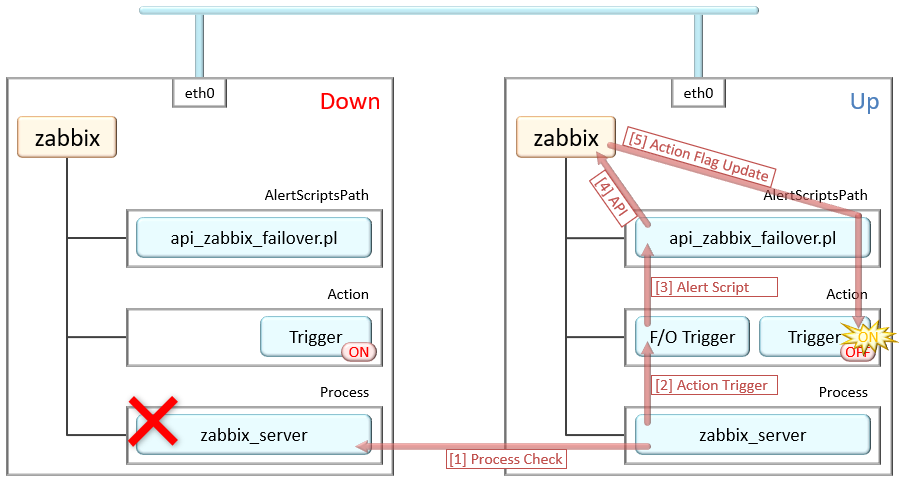
この主系が落ちた時に副系からアラートが上がらない設計問題を解決する為、
副系から主系にZabbixプロセスの内部監視を行い、
プロセスが落ちている時は副系のトリガーアクションを有効化するスクリプト(api_zabbix_failover.pl)を作成した。
主系のZabbixプロセス停止を検知すると、副系のトリガーアクションステータスを切り替えるトリガーが発動し、
ステータスを切り替えるアクションスクリプトを実行する様にしている。
結果、スクリプトが副系のZabbix APIを叩いてアクショントリガーを有効にしてアラート発砲出来る様になる。
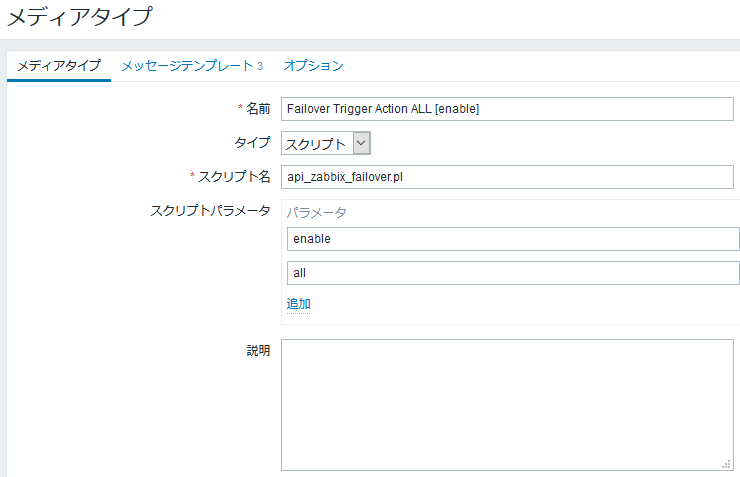
スクリプトを実行するメディアタイプは上の通り。
引数を与える事で有効化・無効化を切り替えつつ、対象範囲を全体・トリガー毎に変更して制御する。
引数はダブルクォーテーションで囲った状態で渡される為、スペースを含む時もそのまま書けば設定出来る。
………
主系が復旧した際は、副系のトリガーアクションを無効化する必要がある為、
発動時に使ったトリガーアクションに、復旧時の実行内容を追加して切り替えスクリプトを再実行する。
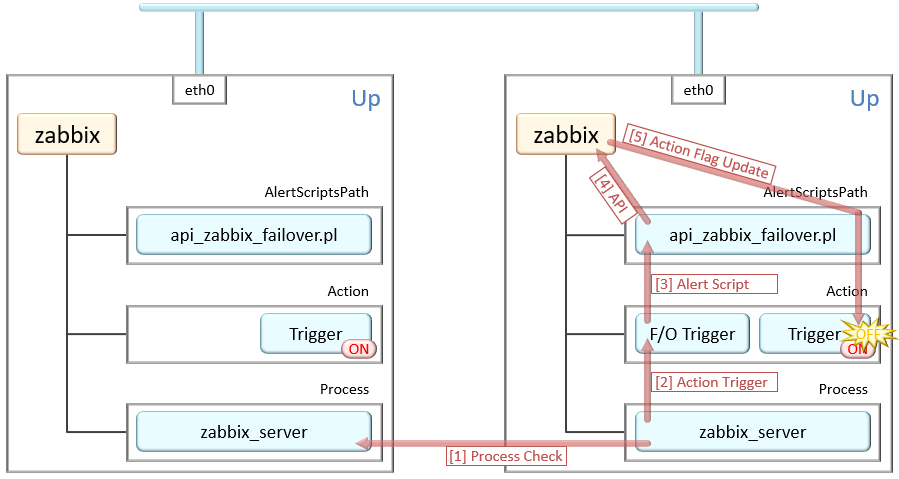
スクリプトで切り替える時のコツは、主系トリガーを常時ONにして副系のON・OFFで制御をする事。
このように片方のみ動かす事で、アラートの上がらないダウンタイムを最小限に出来るのと、
切り替え動作の設計が行いやすくなる。
………
サービス提供するサーバやNW機器を二重化するのは当たり前だが、監視サーバの二重化は忘れがちだと思う。
HinemosとかならHA機能があるので冗長化しやすいが、Zabbixは機能が無いので自力で組む必要がある。
とは言っても、Zabbix APIを叩けば管理画面の操作が大体出来るのでアイディア次第で作る事が出来る。
ググればAPIの叩き方は情報が出てくるので、やった事が無い人はコレを機に挑戦してみて欲しい。
トリガーアクション切り替えスクリプトのサンプル
トリガーとメディアタイプの設定方法はQiita辺りに図解もされているのでこの場は割愛。
今回作成したトリガーアクション切り替えスクリプトは次の処理に特化して作りました。
何が起きても利用者の自己責任を前提に、興味ある人はそのまま使ったり改造してみてください。

MD5:A6C05EF05A7719CC772A28BF95F9410E
実行方法はスクリプトに直接書いてあるヘルプを読めばわかる筈ですが、
基本的な実行方法とオプションの組み合わせは次の通りとなります。
例えば『Sample Action』という名前のトリガーアクションが存在する場合は次の通りとなります。
| 実行オプション |
実行結果の説明 |
| $ api_zabbix_failover.pl enable all |
全てのトリガーアクションステータスを有効化 |
| $ api_zabbix_failover.pl enable ”Sample Action” |
Sample Actionのトリガーを有効化 |
| $ api_zabbix_failover.pl disable all |
全てのトリガーアクションステータスを無効化 |
| $ api_zabbix_failover.pl disable “Sample Action” |
Sample Actionのトリガーを無効化 |
スクリプトはPerlとShellコマンドの組み合わせで書いていますが、
モジュールは出来る限り使わない様にしているので大体のLinux環境で動作する様に設計しています。
スクリプト13~16行目の変数に、Zabbix APIのユーザ情報や接続先ZabbixServerのFQDNを設定し、
上記の様なコマンドを打ち込めばAPIを叩いて動きます。
« 続きを隠す