
[ns-lab BB] 新環境のデータベース構成
以前、自鯖データベースにmaxscaleを採用し、負荷分散構成に変更した事を書いたが、
新自鯖基盤が本番稼働しだした事もあり、備忘録も兼ねて改めて構成を紹介しようと思う。
………
- 旧環境について
自鯖基盤はデータベースを用いるアプリケーションが複数稼働しており、
その中でも特に重要なのが「メールユーザ管理」「ブログ記事データ」「サーバ監視zabbix」の3つとなる。
旧環境は必要に応じて機能追加してきた経緯もあり、各サーバにデータベースも同梱させる構成を取っていた。
ただ、システム規模が大きくなるに連れ、データベースの肥大化と要求スペックの増加がネックになりつつも、
アプリサーバに同梱させる構成の都合上、スケールアップ・スケールアウト出来ないのが課題だった。
また、データベース本体のアップグレード・バックアップ取得もサーバ毎に実施する必要があった為、
自動化を進めたとしても、サーバ管理コストの絶対数が上がってきていた。
そんな中、コミケで頒布されていたIT技術島の冊子を読むと、
HAProxy・MySQL Routerを用いたDBクエリ負荷分散、クラスタリング手法が紹介されていた。
『これは使える!』と思い技術調査を開始。
結果、エンタープライズでも使えそうな事例だったので自鯖基盤に採用した。
- システム構成
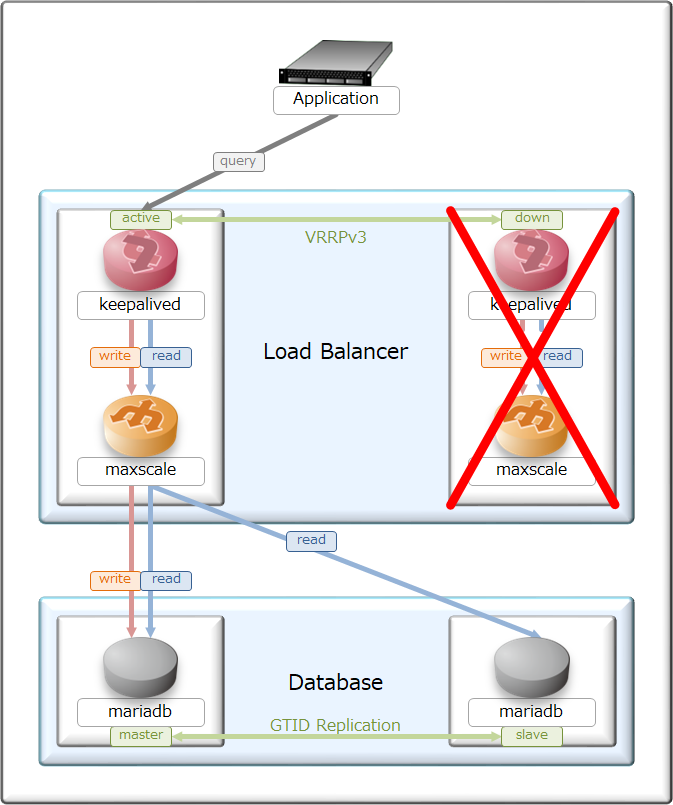
そんな事もあり、出来上がった現環境の負荷分散型データベースがこちら。
構成をシンプルにしたかった事もあり、フロントエンドはmaxscaleを用いてクエリ分散をしつつ、
maxscale自体はkeepalived(VRRP)でL3冗長化をしてみた。
実際にクエリを捌くバックエンドDBには、MariaDBを採用しつつGTIDレプリケーションをしてみた。
ちなみに、第2案としてMariaDB Galera Clusterを用いたクラスタリングも検討したが、
構成が複雑になる上、奇数台数でクラスタを組まないと障害時にスプリットブレインが発生するので没にした。
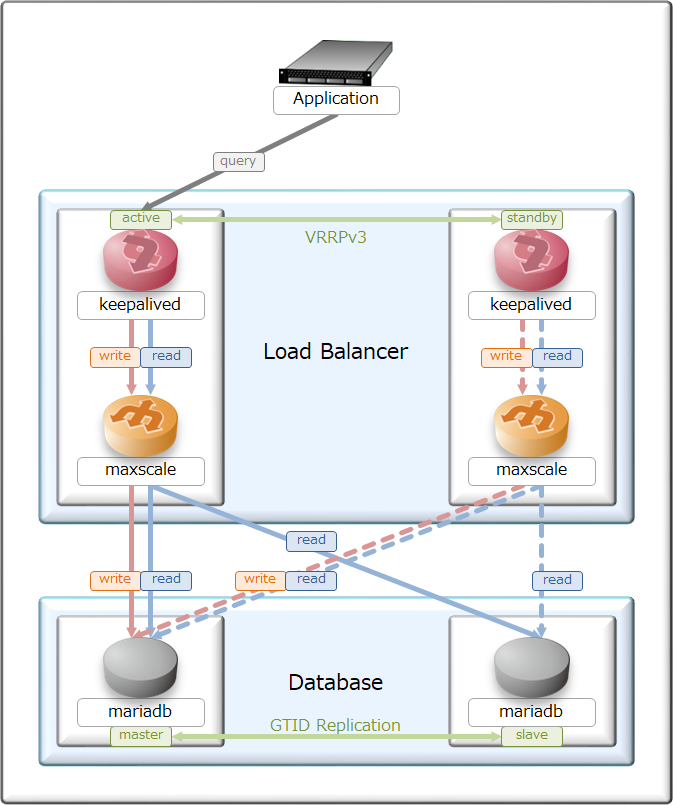
このシステム構成を取ると、writeクエリが1箇所に集中するのが課題だが、
書き込み対象が集中する事によって、クラスタ構成時に必要なトランザクションロックを考えなくて良いのと、
一番やりたかった読込み処理の負荷分散が出来る上、
DB本体がクエリを捌けなくなったらスケールアウトが楽に出来るので採用した。
ロードバランサ・リバースプロキシとして使い慣れている、HAProxyを用いた構成を検討した時期もあったのだが、
データベースのmaster停止時、slaveをmasterに昇格する作業が面倒だったのと、
HAProxyとmaxscaleの処理速度を比較した際に、maxscaleに軍配が上がったのでHAProxy案は没にした。
………
- システム障害動作
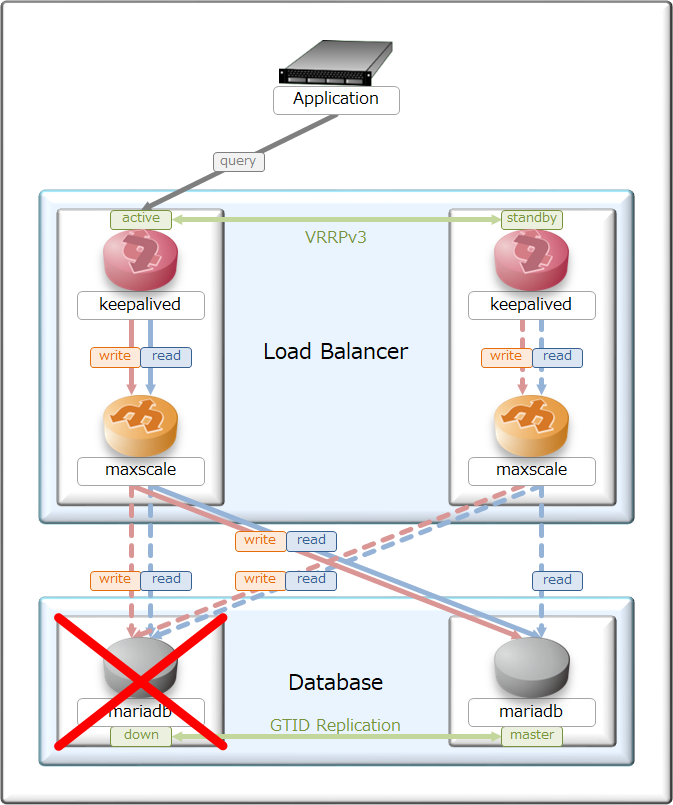
全体の基本設計はActive/Standbyを採用し、それぞれ対となるサーバ・アプリで切り替わる様にしてある。
ただし、ステートフルインスペクションは実装していないので、待機系に移った時はセッション断が発生する。
大多数のアプリケーションなら、セッションを張り直したりして瞬断が発生しても上手く動作する事が多いが、
zabbixはDBセッションを維持し続ける事を前提に設計してある為、
正常系が倒れて待機系に切り替わるとDB書き込みが滞留した後、プロセスがクラッシュして停止する欠点がある。
これはオフィシャルでも議論が続いており、解決策は「zabbixのログを監視してDB断を検知したら再起動」となる。
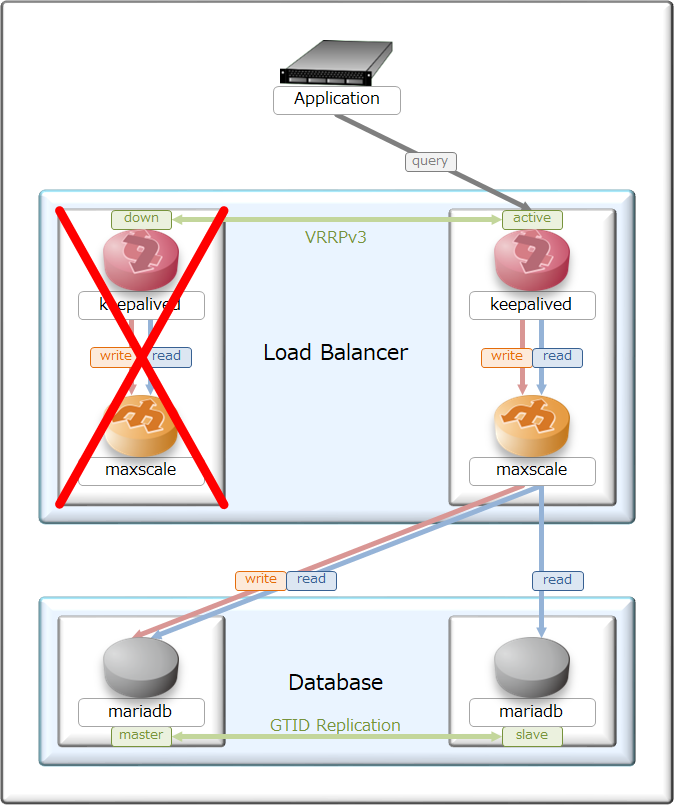
zabbixの様な特殊ケースは置いて、基本設計はプロセス停止後1~3秒で待機系に切り替わる様に設定した。
サーバメンテナンスの時、意図的にフェールオーバー・フェールバックを発生させてみたが、
設計通りにシステム切り替えと、昇格・降格処理を行う事が出来た。
ちなみに、maxscaleが倒れた時はMariaDBへのヘルスモニタも停止するが、
MariaDBが倒れた時はmaxscaleからのヘルスモニタが来続けており、
MariaDB復活直後から2~4秒ほど正常性確認をした上でクエリが振り直される様にしてある。
master障害後に自動復旧させるか否かは設計する人の考えで変わってくるが、
今回は自鯖環境な上、データの整合性が崩れてもバックアップからリストアさせる事が許容出来るので、
負荷分散に再追加するように設定してある。
ただ、master/slaveの昇格・降格については自動で復旧しないようにした。
これは、出来る限りレプリケーション方向を変更したく無い為の設計方針となっている。
………
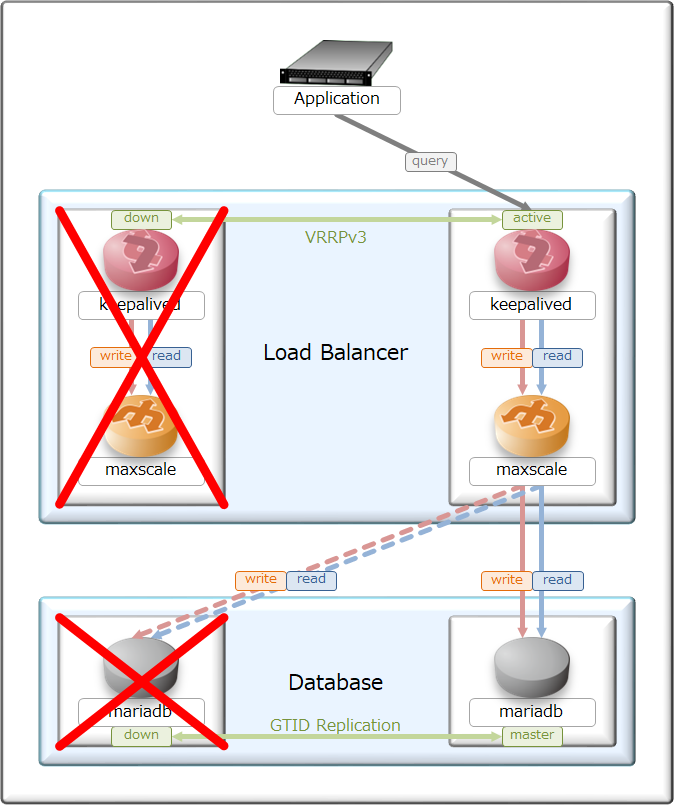
- 待機系切り離し
正常稼働時に待機系が倒れた時についても、システム切り離しを自動で行い、
復旧時は自動的に負荷分散に追加する様にしてある。
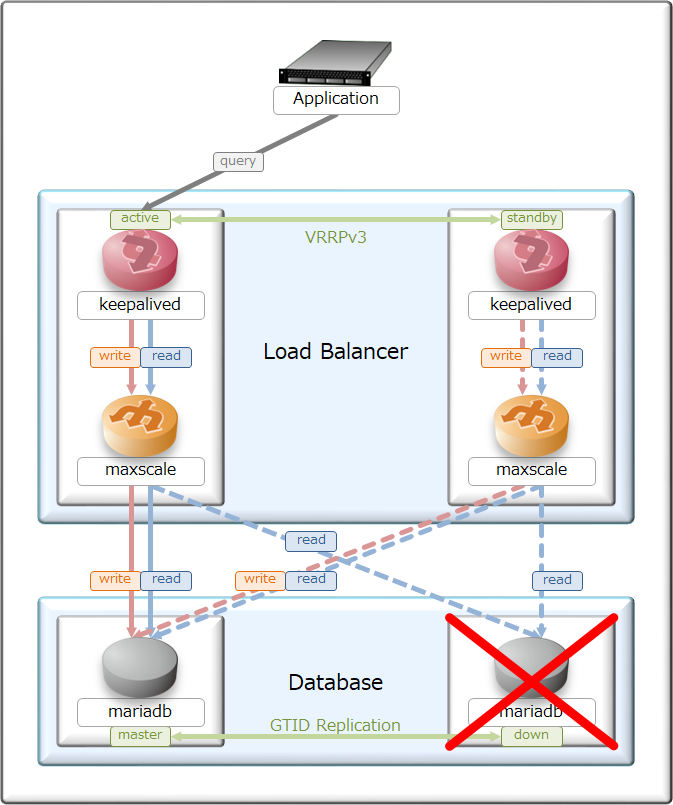
この設計にしておく事で、メンテナンス時に待機系から手を加える事が出来るのと、
ミスが発生した時も正常系を元に復元する事が出来るのがメリットとなる。
………
自鯖刷新で特に力を入れたのが、ロードバランサ・データベースの連携部分だった事もあり、
システム設計・構築作業・動作検証に時間を要したが、課題を払拭する事が出来たので良かった。
maxscaleを用いたデータベース負荷分散手法は、Amazon RDSを利用する場合にも応用出来るので、
自鯖で慣れておく事で、本業にも役立てる事が出来る。
VRRPを用いたフロントエンド冗長化を行った都合上、各サーバを同一セグメントで立てる必要があったが、
グローバルロードバランサと、遠隔レプリケーションを使えば拠点レベルでの冗長化も出来る様になる。
稼働してから日が浅い為、実データも数ギガしか無いが、それなりに成長しだしたデータベースなので、
スキルを修得しながら今後も自鯖で遊んでいこうと思う。




